Création de votre jeu de données pour le projet 2#
Consignes
À partir de la séance 7, vous allez travailler sur votre propre jeu de données d’images et, comme dans le projet 1, apprendre à les classifier selon deux classes.
Cette feuille contient les consignes pour collecter et préparer vos images. Commencez dès cette séance terminée et profitez des occasions offertes par les vacances. Vous devrez avoir terminé avant le mardi 27 février, afin que vous puissiez en discuter avec votre chargée ou chargé de TP lors de la séance 6.
Choix des classes#
Vous devez choisir des images à classifier en deux classes à partir d’attributs (typiquement au nombre de deux) sur lequel l’apprentissage sera effectué. Nous vous donnons ici quelques recommandations, d’une part pour éviter les problèmes techniques, et d’autre part pour que la classification ne soit ni trop simple ni trop difficile.
Voici quelques exemples de classes qui ont bien marché les années précédentes :
des fleurs, des feuilles d’arbres,
des photos de personnages de jeu vidéo (minecraft, zelda, …)
des insectes (coccinelles rouges ou jaunes, mouches/moustiques)
Après quatre années d’enseignement de cette UE, nous vous recommandons de prendre toutes les photos vous même, avec le même téléphone, et dans la même orientation.
Attention
Remarque
Si malgré nos recommandations vous souhaitez prendre des images d’internet, c’est possible, en étant particulièrement vigilant sur l’homogénéité de la dimension et du format des images: monochrome versus couleur, avec ou sans transparence, png versus jpg, etc …
Indication
À chacun son défi!
En fonction du défi que vous souhaitez relever, vous pouvez choisir des images plus ou moins difficiles à classifier. Voire corser votre défi avec, par exemple, (plus de deux classes d’images, …). Discutez en avec votre chargée ou chargé de TP!
Un choix de classe judicieux vous rapportera un point supplémentaire pour la Soutenance du Projet 2.
Collecte des données#
Voici une liste de points de vigilance lors de la collecte de vos données:
Le nombre d’images:
Chaque classe devra contenir entre 10 et 30 images chacune.
Le format des images:
Pour simplifier la préparation des données, vos images doivent toutes avoir le même rapport hauteur / largeur – et notamment la même orientation (carrée, portrait ou paysage) – et le même extension (
.png,.jpg,.jpeg).
L’arrière-plan (ou background):
L’avant plan doit bien ressortir de l’arrière plan: pas de banane sur fond jaune!
L’arrière plan soit homogène d’une photo à l’autre: éviter les biais, avec par exemple des fraises sur fond vert et des pommes sur fond bleu.
L’avant plan (ou foreground)
L’avant plan doit avoir toujours a peu près la même taille.
Les deux classes doivent avoir des couleurs proches mais quand même différentes.
Les deux classes doivent avoir des formes différentes ou bien un template moyen différent (cas des smiley du projet 1).
Astuce
Bon à savoir
Les images au format JPEG ne prennent pas en compte la transparence; elles n’ont donc que trois couches (R, G et B), alors que les images au format PNG en ont typiquement quatres (R, G, B, transparence).
Chargement et préparation des données#
[ ] Déposez votre propre jeu de données dans un sous-dossier
datade~/IntroSciencesDonnees. Vous pouvez pour cela utiliser les boutonsNouveau dossieretChargez vos donnéesdans la barre de gauche de JupyterLab. Voir la figure avec les consignes en rouge et bleu respectivement. Notez que vous pouvez faire cette opération directement depuis votre téléphone.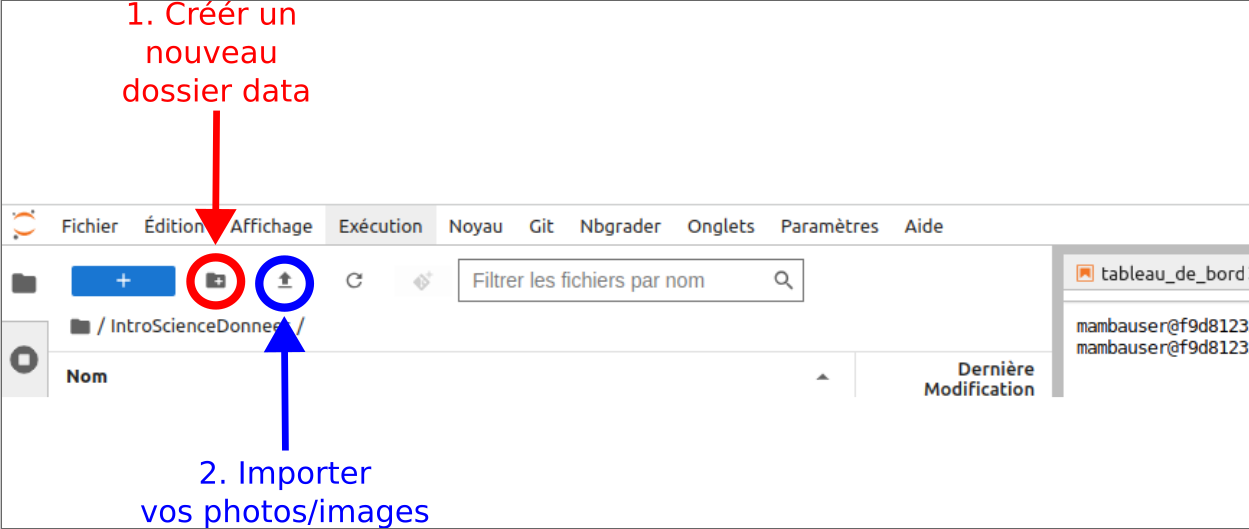
[ ] Suivez les mêmes conventions de nommage que lors du premier projet:
a01.jpg,a02.jpg, … pour les images de la première classe;b01.jpg,b02.jpg, … pour les images de la deuxième classe.
[ ] Vérifiez la taille individuelle des images en (1) ouvrant un terminal et (2) en tapant:
cd ~/IntroScienceDonnees/data ls -lh
Si elle dépasse 50ko par image, réduisez la résolution pour limiter les temps de calcul et la taille de votre dépôt avant de démarrer le projet 2. Pour cela, utilisez la commande ci-dessous, disponible sur JupyterHub et en salles de TP :
cd ~/IntroScienceDonnees/data mogrify -geometry 256x256 *.jpg
Vous pourrez ensuite les redimensionner et les recadrer en Python une fois que le TP6 aura été fait.
Astuce
Information
Dans l’exemple exemple ci-dessus, nous avons déposé des images au format jpg. L’exemple est à ajuster en fonction du format de vos images.
Vérifications#
Après avoir déposé vos images, et éventuellement ajusté leur extension à la ligne suivante, lancez les tests qui suivent pour quelques vérifications.
extension = 'jpg'
from intro_science_donnees import * #les librairies classiques pour ISD (numpy, PIL...) y sont incluses
# Configuration intégration dans Jupyter
%matplotlib inline
dataset_dir = os.path.join('..', 'data')
images_a = load_images(dataset_dir, f"a*.{extension}")
images_b = load_images(dataset_dir, f"b*.{extension}")
images = pd.concat([images_a, images_b])
image_grid(images, titles=images.index)
assert len(images_a) >= 10, "Vous devez avoir au moins 10 images dans la classe A."
assert len(images_b) >= 10, "Vous devez avoir au moins 10 images dans la classe B."
aspect_ratios = [ image.height / image.width for image in images]
assert abs ( max(aspect_ratios) - min(aspect_ratios) ) <= 0.1, \
"Vos images n'ont pas toutes le même rapport hauteur / largeur (aspect ratio)"
from logging import warning
for name,image in images.items():
if image.width > 256: warning(f"Image {name} trop large")
if image.height > 256: warning(f"Image {name} trop haute")
Mélanomes malins et bénins#
Dans le cas ou vous n’auriez aucune idée de classe, vous pourrez utiliser un jeu de données de mélanomes qui sert à développer un algorithme de reconnaissance de grain de beauté à risques de cancer versus des mélanomes bénins. Les mélanomes malins ont tendance à avoir un contour. On reconnait un mélanome malin selon sa catégorie ABCDE:
A = asymétrie (la moitié du grain de beauté ne colle pas avec l’autre moitié.);
B = bord (les bords sont irréguliers);
C = couleur (varie d’une zone à l’autre);
D = diamètre (il est gros);
E = évolutivité (il change au cours du temps).
from intro_science_donnees import * #les librairies classiques pour ISD (numpy, PIL...) y sont incluses
# Configuration intégration dans Jupyter
%matplotlib inline
dataset_dir = os.path.join(data.dir, 'Melanoma')
images = load_images(dataset_dir, "*.jpg")
image_grid(images, titles=images.index)