Cours 7: Deep Learning et classification d’images#
Précédemment
Chaine de traitement d’analyse de données
Application aux images : extraction de features
Classificateurs
Préparation des données : traitement d’images
Cette semaine
Deep Learning et classification d’images
Introduction : Deep Learning ou apprentissage profond#
L’apprentissage statistique (Machine Learning) : ensemble de techniques permettant d’estimer des règles à partir de données
L’apprentissage profond (Deep Learning) : apprentissage statistique reposant sur des réseaux neurones dont les dimensions vont apporter une plus ou moins grande complexité à l’établissement des règles.
Quand avons nous déjà parlé d’apprentissage profond / réseau de neurones ?
Avec le perceptron, au CM5
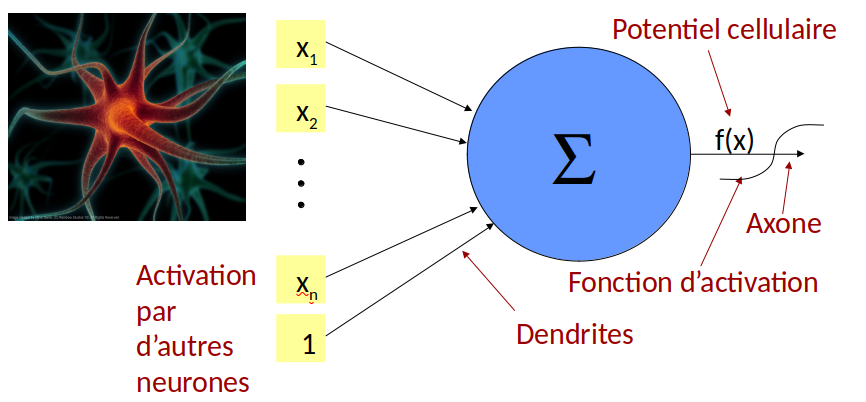
Les neurones en biologie#
Neurones = cellules assurant la transmission d’un signal dans notre organisme (des dentrites jusqu’aux axones terminaux).

Apercu du mécanisme#
Activation (dendrites): entrée de molécules de signal
Transformation en signal électrique et transport le long de l’axone (par une variation de la concentration en ions entre l’environnement intra et extracellulaire)
Arrivée : interprétation en une action ou bien en un transfert vers un autre neurone (par sécretion de molécules de signal).
Quelques statistiques sur les neurones#
\(10^{11}\) = 100 milliards de neurones par individu (équivalent au nombre d’étoiles dans la Voie Lactée)
nerf sciatique = le plus long (> 1m)
\(10^{14}\) synapses, zones de contact entre neurones chez l’adulte

Les premiers neurones en informatique#
McCulloch et Pitts, 1943 Le premier neurone artificiel (modélisation mathématique des neurones biologiques)
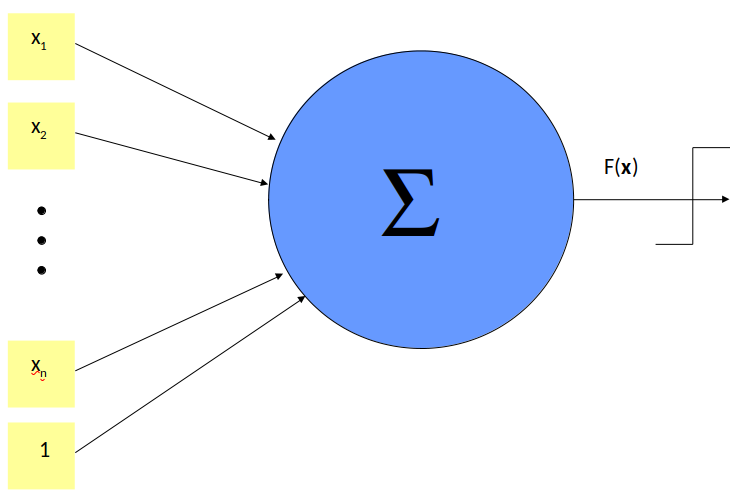
Pouvez vous le décrire ?
un seul neurone
une fonction d’activation \(F\), de type « tout ou rien » (seuil d’activation)
Un signal d’entrée binaire \(x_j = 0 \) ou \(1\)
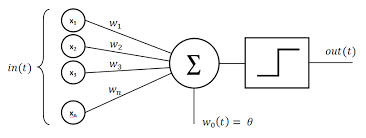
Perceptron (Rosenblatt, 1957)#
Premier algorithme d’apprentissage supervisé dont l’objectif est de distinguer 2 classes. L’unique couche du perceptron contient un neurone et calcule une combinaison linéaire \(w_0 + \sum w_j x_j\) des signaux \(x_1,...x_n\). On applique alors une fonction d’activation et on transmet en sortie le résultat
Les fonctions d’activation (les plus simples)
L’identité (pour les problèmes de régression)
Seuil d’activation (pour les problèmes de classification)
Intervalles d’activation (si on a plus de 2 classes)
Autres fonctions plus complexe, on en mentionnera quelques unes un peu plus tard
Perceptron multi-classe#
Une proposition parmi d’autres si on a \(C>2\) classes.
pas 1 mais \(C\) neurones dans la couche de sortie (un neurone par classe)
les \(n\) neurones de la couche d’entrée sont tous connectés à chacun des neurones de sortie
on a donc \(n\times C\) poids de connexions, notés \(w_j^c\)
les classes sont supposées non chevauchantes
Le deep learning comme réseau de neurones#
Réseau de neurones artificiel : un ensemble de modèles (classifieurs par ex.) dont l’architecture est articulée en couches. Les couches sont composées de différentes transformations non linéaires: des couches de perceptron, des convolutions ou autres transformations.
Ces architectures manipulent des données brutes, sans utiliser d’attributs: les attributs sont en quelque sorte appris par le réseau.
Le réseau le plus simple est un réseau entièrement connecté, mais il est difficile à optimiser !
Poids
Quand le réseau fait une prédiction, les valeurs des données brutes (pixels) sont propagées dans le réseau jusqu’à donner le résultat en sortie.
Les poids sont les paramètres appris par le réseau, associés aux neurones et optimisés lors de l’entraînement.
L’entrainement se fait selon la technique de la descente de gradient (vous le verrez en IAS en L3)
Spécificité des réseaux de neurones
les valeurs d’entrée sont les données brutes et non plus les attributs.
les poids deviennent en quelque sorte des attributs de nos images
Perceptron multi-couche (MLP, multi layer perceptron)#
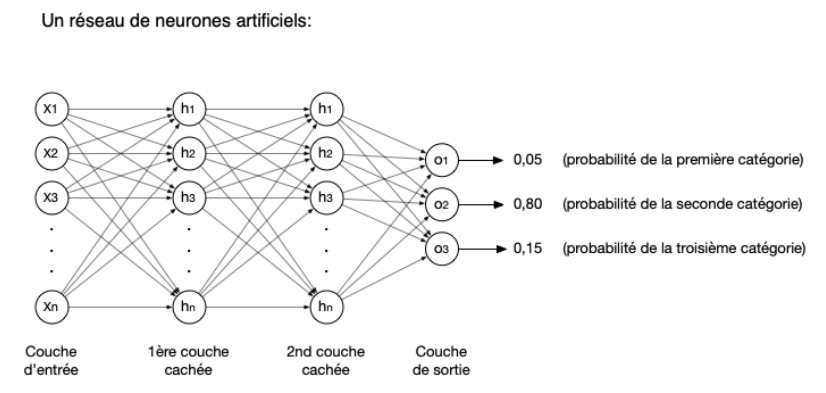
On en a utilisé un lors du CM5 et avec Marcelle.
Les couches intermédiaires sont appelées couches cachées (hidden layers).
Chaque neurone d’une couche intermédiaire ou de la couche de sortie, recoit en entrée les sorties des neurones de la couche précédente
Il n’y a pas de cycle
La complexité vient des fonctions d’activation qui peuvent etre complexes
Réseaux de neurones convolutionnels - Convolutional neural network, CNN ou ConvNet#
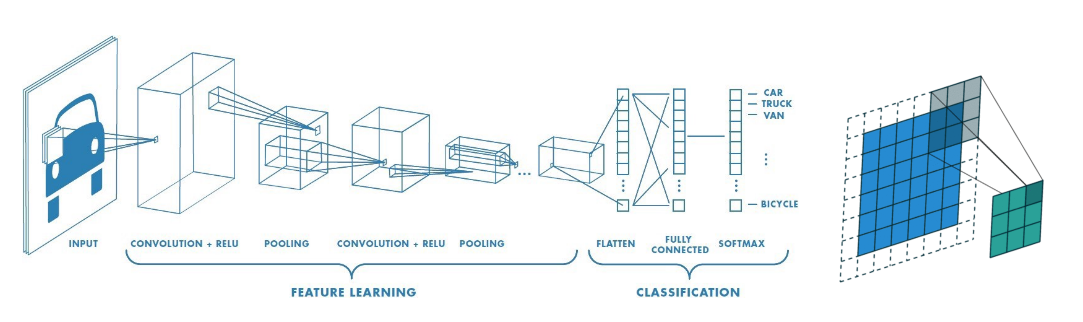
utilisé pour le traitement d’images
multiples perceptrons empilés
chaque perceptron traite une sous-tache
Traitement convolutif#
Définition lors du CM6.
Organisation des CNN#
Succession de plusieurs type de couches:
Couche de convolution
Couche d’activation
Couche de compression
Couche entièrement connectée
Couche de convolution#
Neurones de traitement : analyse une sous-image selon un mode de convolution défini
Trois hyperparamètres : la profondeur, le pas et la marge.
Profondeur : nombre de noyaux de convolution
Pas : décalage des noyaux de convolution (avec ou sans chevauchement)
Marge : la taille des marges de l’image pour gérer les extrémités lors des calculs de convolution
Dans une même couche, les valeurs des paramètres des neurones sont tous identiques.
Couche de d’activation ou de correction#
Opère une fonction d’activation sur les sorties des neurones précédents. Par rapport aux fonctions d’activation précédentes, on notera qu’il existe aussi:
La correction ReLU (abréviation de Unité Linéaire Rectifiée) : \(f(x)=\ max(0,x)\). On est linéaire une fois activé.
La correction par la fonction sigmoïde \(f(x)=(1+e^{-x})^{-1}\).
Couche de compression#
Neurones de pooling : regroupent les sorties de convolution
forment une image intermédiaire qui servira de nouvelle « image » d’analyse
Le pooling permet de réduire la dimension des images intermédiaires
réduit le risque de surapprentissage
Couche entièrement connectée (FC, fully connected)#
En fin de réseau, on utilisera des couches entièrement connectées aux sorties de la couche précédente. Leurs fonctions d’activations peuvent être calculées avec une multiplication matricielle et permettent in fine de classifier nos images.
Exemple d’une architecture connexioniste#
Exemple d’un réseau de neurone profond, sur le site créé par Adam Harley de l’Université Carnegie Mellon. Il présente un réseau convolutionnel pour la reconnaissance de chiffres manuscrits.

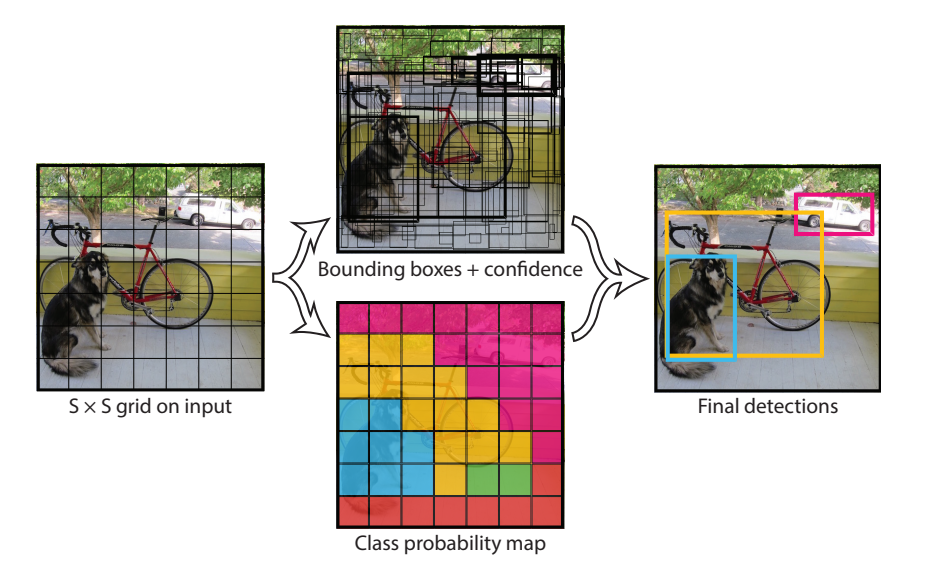
Region-based CNN (2013)#
On peut aussi spécialiser régionalement notre analyse. On parle alors de R-CNN (region based CNN, à ne pas confondre avec les RNN pour recursive neural networks – hors programme).

On identifie les régions d’interet (ROI, regions of interest) en utilisant un mécanisme de recherche sélective
Chaque ROI est un ensemble de rectangles (idéalement, entourant nos objets)
Ensuite, chaque ROI est donné comme entrée d’un réseau de neurone puis est classifié
RCNN en python
Il existe des réseaux pré-entrainés, capables de reconnaitre de nombreux objets de la vie quotidienne.
C’est très facile à utiliser, mais ca ne vous dit pas comment ils ont été entrainés ni construits !
La librairie OpenCV contient le réseau YOLO qui est entrainé
cvlib (computer vision library) contient aussi un réseau préentrainé
Principales différences entre le deep et le machine learning#
La complexité des modèles;
La quantité de données requise est plus importante pour le deep learning (en lien avec le point 1);
Ces réseaux profonds comptent beaucoup de paramètres (neurones) à optimiser. Ils nécessitent des infrastructures spéciales pour les entraîner: de puissantes cartes graphiques (GPU), comme celles utilisées pour les jeux vidéos, qui permettent de paralléliser les calculs. Nous ne disposons pas de telles infrastructures sur le service JupyterHub de l’université.
Transfert Learning#
Dans le projet 2, nous allons donc voir comment transférer les connaissances apprises par un réseau pour l’adapter à votre problème: On appelle cela l”apprentissage par transfert (Transfer Learning).
Une révolution du deep learning : la vision par ordinateur#
Jeu de données de référence : ImageNet#
Collaboration entre l’université de Stanford et celle de Princeston.
15 millions d’images et 22.000 catégories.
ImageNet Large Scale Visual Recognition Challenge (ILSVRC) :#
De 2010 à 2017:
1 000 images par catégorie,
50 000 images de validation,
150 000 images de test.
Objectif : faire avancer la recherche dans le domaine de la vision par ordinateur
ImageNet continue à être utilisé dans de nombreux projets comme jeu de test.
Quelques exemples connus de CNN qui ont remporté l’ILSVRC#
Inception network de Google

nouveau concept : module Inception
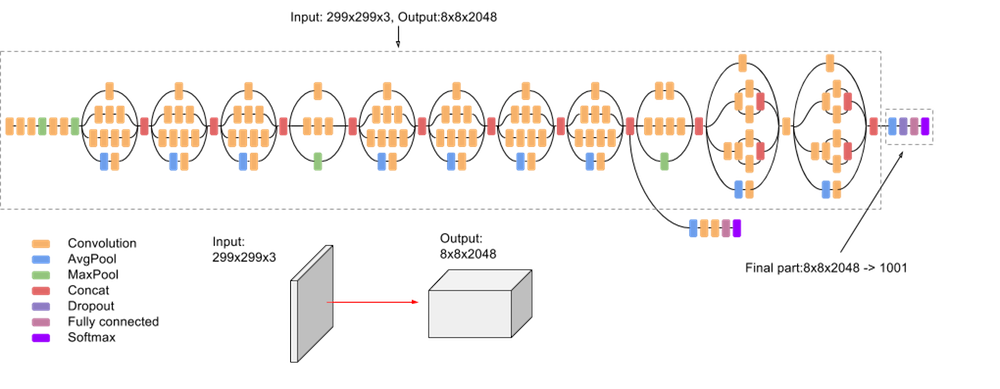
22 couches
ResNet de microsoft research Asia
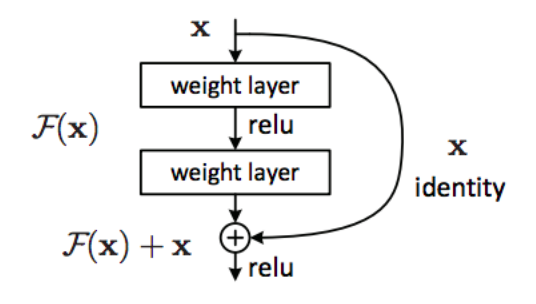
nouveau concept : introduire une connexion de raccourci qui saute une ou plusieurs couches.
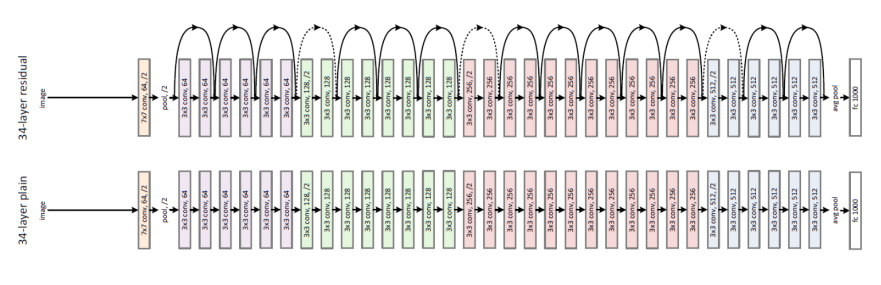
152 couches !
Conclusions sur le Deep Learning#
Deep Learning: réseau de neurones, perceptron multi-couches, CNN …
Grand jeu de données réputé difficile : ImageNet, qui sert de jeu de test
Deux exemples d’architectures de CNN qui ont marqué le domaine de la vision par ordinateur
Perspectives#
CM8: Evaluation de la performance des classificateurs
CM9: Impact écologique et impact sociétal de l’intelligence artificielle
Il y aura un deuxième QCM bientot !